Two important things happened on January 20, 2025. In Washington, D.C., Donald Trump was inaugurated as President of the United States. In Hangzhou, China, a little-known Chinese firm called DeepSeek released R1, an AI model that industry watchers called a “Sputnik moment” for the country’s AI industry.
“Whether we like it or not, we're suddenly engaged in a fast-paced competition to build and define this groundbreaking technology that will determine so much about the future of civilization,” said Trump later that year, as he announced his administration’s AI action plan, which was titled “Winning the Race.”
There are many interpretations of what AI companies and their governments are racing towards, says AI policy researcher Lennart Heim: to deploy AI systems in the economy, to build robots, to create human-like artificial general intelligence.
"I think in most metrics, the U.S. is clearly leading,” he says. But Heim notes that getting a clear picture of AI progress and adoption is challenging: “The best metrics are the numbers we don't have.”
These six graphs show where the U.S. is ahead of China, what’s driving that lead—and why it could be tenuous.

“Right now, compute is arguably the single biggest driver of AI progress,” says Daniel Kokotajlo, executive director of the AI Futures Project, a research group that forecasts the future of AI progress, referring to the computer chips used to train AI models.
That’s bad news for Chinese firms, which have been limited in their access to compute—the chips used to train and run AI models—since 2022, when the Biden administration restricted the export of the advanced manufacturing equipment used to produce the chips, and then the chips themselves in 2023.
“Money has never been the problem for us; bans on shipments of advanced chips are the problem,” said Liang Wenfeng, CEO of DeepSeek in July 2024.
However, export rules announced in January by the Trump administration could give Chinese companies access to 890,000 of Nvidia’s H200 AI chips—more than double the number of chips that Chinese manufacturers are expected to produce in 2026, according to a report by the Center for a New American Security.
“Limited access to advanced chips has been the primary constraint on China’s AI progress. The new export rule will significantly boost China’s AI capabilities,” Janet Egan, one of the report’s authors, told TIME. “The U.S. is essentially equipping its leading strategic competitor.”
It remains to be seen whether the Chinese companies will be able to take advantage of the newly available chips—Chinese customs officials initially blocked imports of the chips, according to reports.
“China has a lot of incentive to look like it might be blocking chips, both in terms of its relationship with Chinese tech companies, because it wants to force them to buy domestic chips, and in terms of its relationship with Washington, because it wants to make Washington think that it doesn't need U.S. chips,” says Chris Miller, author of Chip War, a bestselling history of the semiconductor industry.

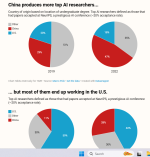
The success of DeepSeek’s R1 model was a sign of what can be achieved by a talented team with limited resources. A Stanford analysis found that more than half of the researchers responsible for the breakthrough “never left China for schooling or work,” challenging “the core assumption that the United States holds a natural AI talent lead.”
China produces far more top AI researchers than the U.S., according to an analysis of authors at NeurIPS, a top AI conference. Many of them end up working in the U.S., but the share working in China more than doubled between 2019 and 2022, and a new $100,000 price tag on visas for foreign talent may further “hurt the innovation and competitiveness of the U.S. industry,” Subodha Kumar, a professor at the Fox School of Business at Temple University, told TIME last year.

AI training is incredibly power-hungry. U.S. AI companies have been falling over each other to secure contracts with energy providers.
Chinese AI companies have a significant advantage in this regard. China has produced more energy than the U.S. since 2010. “Of all the key inputs into AI, energy is the one where the U.S. is least competitive,” says Miller.
For now, China’s AI development is bottlenecked by its lack of AI chips, but if its stock increases—either through relaxed export controls of American chips, or through increased domestic production—the country’s ready access to energy could be critical.

For the time being, America’s control of AI chips and larger share of top talent has allowed it to produce the world’s most capable large language models (LLMs). Chinese LLMs have lagged behind American models by seven months on average, according to Epoch AI, an AI research company.
Moreover, Chinese models’ competitiveness might be partly due to “distillation,” where developers use outputs from more capable models to train their own models, says Heim. Some users reported that Chinese firm DeepSeek’s model said that it was “ChatGPT, a language model developed by OpenAI,” when asked to identify itself.
“Without distillation, I expect the gap in AI model performance would be bigger,” Heim told TIME.

“Revenue is people paying for things they find useful,” says Miller. “The best metric, I think, of AI deployment is the revenue that accrues to AI products.”
Alibaba—which makes the Qwen series of models, among the most capable coming out of China—is publicly traded, and therefore is one of the country’s few AI developers that also publishes revenue figures.
However, developing Qwen is a side hustle for the company’s Cloud Intelligence division, which is the largest provider of web services in the country, making the group’s revenue an upper bound on the money that the company makes on its AI models.
Even so, it’s a figure that American AI startups—founded at least six years later and concentrated solely on AI development—are approaching rapidly. In September, Alibaba Cloud posted an annualized revenue of $22 billion. Two months later, OpenAI’s CFO Sarah Friar wrote that OpenAI had exceeded $20 billion.

 time.com
time.com
“Whether we like it or not, we're suddenly engaged in a fast-paced competition to build and define this groundbreaking technology that will determine so much about the future of civilization,” said Trump later that year, as he announced his administration’s AI action plan, which was titled “Winning the Race.”
There are many interpretations of what AI companies and their governments are racing towards, says AI policy researcher Lennart Heim: to deploy AI systems in the economy, to build robots, to create human-like artificial general intelligence.
"I think in most metrics, the U.S. is clearly leading,” he says. But Heim notes that getting a clear picture of AI progress and adoption is challenging: “The best metrics are the numbers we don't have.”
These six graphs show where the U.S. is ahead of China, what’s driving that lead—and why it could be tenuous.
“Right now, compute is arguably the single biggest driver of AI progress,” says Daniel Kokotajlo, executive director of the AI Futures Project, a research group that forecasts the future of AI progress, referring to the computer chips used to train AI models.
That’s bad news for Chinese firms, which have been limited in their access to compute—the chips used to train and run AI models—since 2022, when the Biden administration restricted the export of the advanced manufacturing equipment used to produce the chips, and then the chips themselves in 2023.
“Money has never been the problem for us; bans on shipments of advanced chips are the problem,” said Liang Wenfeng, CEO of DeepSeek in July 2024.
However, export rules announced in January by the Trump administration could give Chinese companies access to 890,000 of Nvidia’s H200 AI chips—more than double the number of chips that Chinese manufacturers are expected to produce in 2026, according to a report by the Center for a New American Security.
“Limited access to advanced chips has been the primary constraint on China’s AI progress. The new export rule will significantly boost China’s AI capabilities,” Janet Egan, one of the report’s authors, told TIME. “The U.S. is essentially equipping its leading strategic competitor.”
It remains to be seen whether the Chinese companies will be able to take advantage of the newly available chips—Chinese customs officials initially blocked imports of the chips, according to reports.
“China has a lot of incentive to look like it might be blocking chips, both in terms of its relationship with Chinese tech companies, because it wants to force them to buy domestic chips, and in terms of its relationship with Washington, because it wants to make Washington think that it doesn't need U.S. chips,” says Chris Miller, author of Chip War, a bestselling history of the semiconductor industry.
The success of DeepSeek’s R1 model was a sign of what can be achieved by a talented team with limited resources. A Stanford analysis found that more than half of the researchers responsible for the breakthrough “never left China for schooling or work,” challenging “the core assumption that the United States holds a natural AI talent lead.”
China produces far more top AI researchers than the U.S., according to an analysis of authors at NeurIPS, a top AI conference. Many of them end up working in the U.S., but the share working in China more than doubled between 2019 and 2022, and a new $100,000 price tag on visas for foreign talent may further “hurt the innovation and competitiveness of the U.S. industry,” Subodha Kumar, a professor at the Fox School of Business at Temple University, told TIME last year.
AI training is incredibly power-hungry. U.S. AI companies have been falling over each other to secure contracts with energy providers.
Chinese AI companies have a significant advantage in this regard. China has produced more energy than the U.S. since 2010. “Of all the key inputs into AI, energy is the one where the U.S. is least competitive,” says Miller.
For now, China’s AI development is bottlenecked by its lack of AI chips, but if its stock increases—either through relaxed export controls of American chips, or through increased domestic production—the country’s ready access to energy could be critical.
For the time being, America’s control of AI chips and larger share of top talent has allowed it to produce the world’s most capable large language models (LLMs). Chinese LLMs have lagged behind American models by seven months on average, according to Epoch AI, an AI research company.
Moreover, Chinese models’ competitiveness might be partly due to “distillation,” where developers use outputs from more capable models to train their own models, says Heim. Some users reported that Chinese firm DeepSeek’s model said that it was “ChatGPT, a language model developed by OpenAI,” when asked to identify itself.
“Without distillation, I expect the gap in AI model performance would be bigger,” Heim told TIME.
“Revenue is people paying for things they find useful,” says Miller. “The best metric, I think, of AI deployment is the revenue that accrues to AI products.”
Alibaba—which makes the Qwen series of models, among the most capable coming out of China—is publicly traded, and therefore is one of the country’s few AI developers that also publishes revenue figures.
However, developing Qwen is a side hustle for the company’s Cloud Intelligence division, which is the largest provider of web services in the country, making the group’s revenue an upper bound on the money that the company makes on its AI models.
Even so, it’s a figure that American AI startups—founded at least six years later and concentrated solely on AI development—are approaching rapidly. In September, Alibaba Cloud posted an annualized revenue of $22 billion. Two months later, OpenAI’s CFO Sarah Friar wrote that OpenAI had exceeded $20 billion.
6 Graphs That Show Who’s Really Winning the US–China AI Race
From compute and talent to energy and revenue, six charts show where the U.S. leads China in AI—and why that lead could prove fragile.
time.com