

When it comes to functional verification of large designs, huge progress is being made in emulation and FPGA-based prototyping (about which I’ll have more to say in follow-on blogs), but simulation still dominates verification activity, all the way from IP verification to gate-level signoff. For many, while it is much slower than hardware-assisted options, it’s easier to setup, easier to debug and easy to parcel out to simulation farms where you can run thousands of regression jobs in parallel.

So Cadence made a shrewd move in acquiring Rocketick last year to provide acceleration help to the simulation-bound. But designs continue to get bigger and hairier so, according to Adam Sherer (Group Dir Marketing at Cadence), they’ve turned the crank some more, this time to an approach that has significant potential for scaling (tis the season for scalability roadmaps). The big news here is that this solution (Xcelium) is now able to efficiently split an Incisive simulation across multiple cores based on a careful examination of dependencies, and it does this in such a way that it can deliver significant acceleration over single-core simulation.

This is no small feat. Many attempts have been made at parallel simulation but have struggled to deliver significant improvement because it has been so difficult to decouple activity in one part of a circuit from any other part. Breaking a circuit into pieces might speed up the pieces but you lose most of that gain in heavy inter-piece communication overhead (that’s my technical term for it). According to Adam, it’s the nature of the SoC verification problem that makes multi-core more effective in this case. Subsystem blocks in an SoC commonly operate concurrently, creating a high density of events which would slow down a simulator needing to run in a single core. But RocketSim can figure out intra/inter-block dependencies and partitions the circuit across cores so it can handle those higher event densities with greatly reduced impact (see the first table below). A similar argument applies to running multiple concurrent test scenarios (a common task in SoC verification); run-times are found to grow much more slowly with number of tests on multi-core than on single-core.
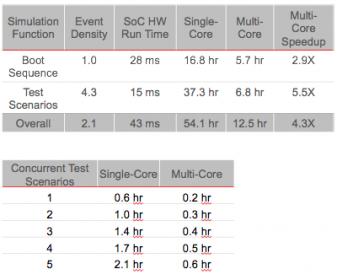
Cadence has done quite a bit to justify a new brand on this creation. First, some applications still work best on single-core, such as IP verification with meaty UVM test-benches. These can’t be partitioned easily, yet Xcelium still offers ~2X speedup for IP sims on that single core over the previous generation. They’ve have also added an improved randomization engine which is both faster and delivers better distributions to help constrained-random reach coverage more quickly. Meanwhile SoC sims are running 5-10x faster on multi-core, again over prior generation performance. This should be of interest in many contexts, for example in DFT sims which tend to be very high activity, also for teams wanting to speed up multi-week gate-level sim signoffs.
Another important point is that the solution is purely software and requires no special hardware. While RocketSim started with GPUs, it now runs on standard server platforms. Cadence apparently has recommended configurations for servers, but otherwise the solution is available to everyone who has access to datacenter-class servers. Which means it can help all simulation users, not just a privileged few.
The cool thing about the multi-core part of this solution is that it scales with available cores. I’m sure you’re thinking – “nah, that’s not right – everyone knows that software parallelization improvements tail off as the number of cores increase”. But I think Cadence is onto something. Even as SoC sizes increase, they’re still made from IPs and even the big IPs are made from little IPs. Cadence won’t share the details of the partitioning algorithm (patent pending), so we’re left to speculate. Certainly the speedup they are seeing is significant, so it seems the IP/bus-based nature of SoC design must make the problem tractable if you have the right engine to attack it. Of course, nothing lasts forever; I’m sure performance will tail off at some point, but I think Cadence probably have quite a bit of runway with this solution.
In the interest of full disclosure, Adam told me that they’re still working on bringing up multi-core support for VHDL. But you SystemVerilog and gate-level users are good to go right now.
Naturally all of this isn’t just on Cadence’s say-so. They have endorsements from ARM and ST in their Xcelium press release. And I imagine a lot more simulation customers are going to be jumping on this bandwagon – who wouldn’t want faster simulation? You can learn more about the solution HERE.
Share this post via:



Comments
0 Replies to “Simulation done Faster”
You must register or log in to view/post comments.