Threads
XF\Mvc\Entity\ArrayCollection Object
(
[entities:protected] => Array
(
[20140] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 51
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20140
[node_id] => 2
[title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[reply_count] => 6
[view_count] => 699
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1714604636
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69844
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1715075078
[last_post_id] => 69963
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20155] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20155
[node_id] => 2
[title] => How to Build a $20 Billion Semiconductor Fab
[reply_count] => 2
[view_count] => 249
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1715006269
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69943
[first_post_reaction_score] => 8
[first_post_reactions] => {"1":8}
[last_post_date] => 1715070375
[last_post_id] => 69960
[last_post_user_id] => 20231
[last_post_username] => Barnsley
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20157] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 59
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20157
[node_id] => 2
[title] => TSMC’s Advanced Packaging Capacity is fully booked for next two years by Nvidia and AMD
[reply_count] => 7
[view_count] => 541
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1715009935
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69945
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1715041010
[last_post_id] => 69957
[last_post_user_id] => 8322
[last_post_username] => hskuo
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20148] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 63
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20148
[node_id] => 2
[title] => Apple M4 chip rumors: Everything you need to know
[reply_count] => 4
[view_count] => 2363
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1714833893
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69910
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1715016722
[last_post_id] => 69951
[last_post_user_id] => 90182
[last_post_username] => siliconbruh999
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20150] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 67
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20150
[node_id] => 2
[title] => Japan's Rapidus fab to compete with TSMC, Samsung for 2nm chips
[reply_count] => 6
[view_count] => 2437
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1714846355
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69923
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1715015029
[last_post_id] => 69950
[last_post_user_id] => 138292
[last_post_username] => MKWVentures
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20156] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 71
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20156
[node_id] => 2
[title] => CHIPS for America Announces $285 million Funding Opportunity for a Digital Twin and Semiconductor CHIPS Manufacturing USA Institute
[reply_count] => 0
[view_count] => 181
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1715006824
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69944
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1715006824
[last_post_id] => 69944
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20141] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 75
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20141
[node_id] => 2
[title] => Legacy Chip Overcapacity in China: Myth and Reality
[reply_count] => 8
[view_count] => 2046
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1714675283
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69868
[first_post_reaction_score] => 2
[first_post_reactions] => {"1":2}
[last_post_date] => 1714976369
[last_post_id] => 69939
[last_post_user_id] => 33967
[last_post_username] => Jert
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20152] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 79
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20152
[node_id] => 2
[title] => TSMC dominates global foundry market with 61% market share in 4Q23, says Counterpoint
[reply_count] => 2
[view_count] => 716
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1714917413
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69934
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1714943012
[last_post_id] => 69937
[last_post_user_id] => 35301
[last_post_username] => Xebec
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20128] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 83
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20128
[node_id] => 2
[title] => TSMC statement on next-generation EUV
[reply_count] => 28
[view_count] => 3180
[user_id] => 5185
[username] => Fred Chen
[post_date] => 1714542308
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69800
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1714912239
[last_post_id] => 69932
[last_post_user_id] => 170880
[last_post_username] => nghanayem
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 80
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5185
[username] => Fred Chen
[username_date] => 0
[username_date_visible] => 0
[email] => chen.t.fred@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 4
[secondary_group_ids] =>
[display_style_group_id] => 4
[permission_combination_id] => 92
[message_count] => 1728
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1333032401
[last_activity] => 1714973449
[last_summary_email_date] => 1605940563
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 2
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 831
[warning_points] => 0
[is_staff] => 0
[secret_key] => 5m-bZq0HRSi9VA-96QONHJeevdQas5S8
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20151] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 87
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20151
[node_id] => 2
[title] => Sam Altman says helpful agents are poised to become AI’s killer function
[reply_count] => 0
[view_count] => 838
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1714859740
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69926
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1714859740
[last_post_id] => 69926
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20114] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 91
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20114
[node_id] => 2
[title] => Intel first quarter 2024 earnings of
[reply_count] => 25
[view_count] => 3845
[user_id] => 322214
[username] => Mooredaddy
[post_date] => 1714093381
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69642
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1714850603
[last_post_id] => 69924
[last_post_user_id] => 332223
[last_post_username] => cr95630
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 88
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 322214
[username] => Mooredaddy
[username_date] => 0
[username_date_visible] => 0
[email] => will.berry109@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/New_York
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 326
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1667481127
[last_activity] => 1715069962
[last_summary_email_date] =>
[trophy_points] => 63
[alerts_unviewed] => 17
[alerts_unread] => 17
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 335
[warning_points] => 0
[is_staff] => 0
[secret_key] => 8NE1Vwjfzn5qX3A-FJ8dQ7tRKjBV_VtS
[privacy_policy_accepted] => 1667481127
[terms_accepted] => 1667481127
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20149] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 95
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20149
[node_id] => 2
[title] => Demand for NVIDIA’s Blackwell Platform Expected to Boost TSMC’s CoWoS Total Capacity by Over 150% in 2024
[reply_count] => 0
[view_count] => 1537
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1714835922
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69911
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1714835922
[last_post_id] => 69911
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20147] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 99
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20147
[node_id] => 2
[title] => Government-backed Japan Investment Corporation (JIC) completes takeover of JSR
[reply_count] => 1
[view_count] => 2537
[user_id] => 5185
[username] => Fred Chen
[post_date] => 1714820688
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69905
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1,"4":1}
[last_post_date] => 1714831612
[last_post_id] => 69909
[last_post_user_id] => 8322
[last_post_username] => hskuo
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 80
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5185
[username] => Fred Chen
[username_date] => 0
[username_date_visible] => 0
[email] => chen.t.fred@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 4
[secondary_group_ids] =>
[display_style_group_id] => 4
[permission_combination_id] => 92
[message_count] => 1728
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1333032401
[last_activity] => 1714973449
[last_summary_email_date] => 1605940563
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 2
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 831
[warning_points] => 0
[is_staff] => 0
[secret_key] => 5m-bZq0HRSi9VA-96QONHJeevdQas5S8
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20072] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 103
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20072
[node_id] => 2
[title] => Huawei Pura 70 smartphone sales start; chip still a mystery
[reply_count] => 10
[view_count] => 2098
[user_id] => 5185
[username] => Fred Chen
[post_date] => 1713624875
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69460
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1714751596
[last_post_id] => 69895
[last_post_user_id] => 29441
[last_post_username] => tonyget
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 80
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5185
[username] => Fred Chen
[username_date] => 0
[username_date_visible] => 0
[email] => chen.t.fred@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 4
[secondary_group_ids] =>
[display_style_group_id] => 4
[permission_combination_id] => 92
[message_count] => 1728
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1333032401
[last_activity] => 1714973449
[last_summary_email_date] => 1605940563
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 2
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 831
[warning_points] => 0
[is_staff] => 0
[secret_key] => 5m-bZq0HRSi9VA-96QONHJeevdQas5S8
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20127] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 107
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20127
[node_id] => 2
[title] => Apple's iPhone factory shift has left a ghost town behind in China
[reply_count] => 17
[view_count] => 1424
[user_id] => 5185
[username] => Fred Chen
[post_date] => 1714540630
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69798
[first_post_reaction_score] => 2
[first_post_reactions] => {"1":2}
[last_post_date] => 1714749537
[last_post_id] => 69892
[last_post_user_id] => 330443
[last_post_username] => Claudio DD
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 80
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5185
[username] => Fred Chen
[username_date] => 0
[username_date_visible] => 0
[email] => chen.t.fred@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 4
[secondary_group_ids] =>
[display_style_group_id] => 4
[permission_combination_id] => 92
[message_count] => 1728
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1333032401
[last_activity] => 1714973449
[last_summary_email_date] => 1605940563
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 2
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 831
[warning_points] => 0
[is_staff] => 0
[secret_key] => 5m-bZq0HRSi9VA-96QONHJeevdQas5S8
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20143] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 111
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20143
[node_id] => 2
[title] => TSMC Jumps Into Silicon Photonics, Lays Out Roadmap For 12.8 Tbps COUPE On-Package Interconnect ?
[reply_count] => 1
[view_count] => 1967
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1714748737
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69888
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1714748791
[last_post_id] => 69889
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20117] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 115
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20117
[node_id] => 2
[title] => TSMC's New N4C
[reply_count] => 30
[view_count] => 3400
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1714143273
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69674
[first_post_reaction_score] => 3
[first_post_reactions] => {"1":3}
[last_post_date] => 1714748606
[last_post_id] => 69887
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11401
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1715057547
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 16
[alerts_unread] => 16
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3502
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20142] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 119
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20142
[node_id] => 2
[title] => World's first programable photonic chip
[reply_count] => 0
[view_count] => 1052
[user_id] => 10499
[username] => Arthur Hanson
[post_date] => 1714734413
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69884
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1714734413
[last_post_id] => 69884
[last_post_user_id] => 10499
[last_post_username] => Arthur Hanson
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 116
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 10499
[username] => Arthur Hanson
[username_date] => 0
[username_date_visible] => 0
[email] => a-j-hanson@att.net
[custom_title] =>
[language_id] => 1
[style_id] => 1
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 2972
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1366028460
[last_activity] => 1714999375
[last_summary_email_date] => 1606051785
[trophy_points] => 83
[alerts_unviewed] => 1
[alerts_unread] => 1
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 341
[warning_points] => 0
[is_staff] => 0
[secret_key] => ta_8_Pj20m6PDO6RnrGK-VnSP_vyhP_m
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20126] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 123
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20126
[node_id] => 2
[title] => U.S. ramps up chip production efforts with taxpayers footing part of the bill - Is it worth it?
[reply_count] => 19
[view_count] => 1089
[user_id] => 36640
[username] => soAsian
[post_date] => 1714513604
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69792
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1714706844
[last_post_id] => 69882
[last_post_user_id] => 20231
[last_post_username] => Barnsley
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 120
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 36640
[username] => soAsian
[username_date] => 0
[username_date_visible] => 0
[email] => jackmtsai@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/Chicago
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 162
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1608139716
[last_activity] => 1715067657
[last_summary_email_date] => 1705155721
[trophy_points] => 28
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 81
[warning_points] => 0
[is_staff] => 0
[secret_key] => 2oKeCTFkGUpMro5tcmj7WaY9HksB13Kw
[privacy_policy_accepted] => 1608139716
[terms_accepted] => 1608139716
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20073] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 127
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20073
[node_id] => 2
[title] => Where is all the power going to come from for AI/ML
[reply_count] => 24
[view_count] => 2010
[user_id] => 10499
[username] => Arthur Hanson
[post_date] => 1713787280
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69484
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1714688698
[last_post_id] => 69877
[last_post_user_id] => 5509
[last_post_username] => milesgehm
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 116
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 10499
[username] => Arthur Hanson
[username_date] => 0
[username_date_visible] => 0
[email] => a-j-hanson@att.net
[custom_title] =>
[language_id] => 1
[style_id] => 1
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 2972
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1366028460
[last_activity] => 1714999375
[last_summary_email_date] => 1606051785
[trophy_points] => 83
[alerts_unviewed] => 1
[alerts_unread] => 1
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 341
[warning_points] => 0
[is_staff] => 0
[secret_key] => ta_8_Pj20m6PDO6RnrGK-VnSP_vyhP_m
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5758
[message_count] => 35759
[last_post_id] => 69963
[last_post_date] => 1715075078
[last_post_user_id] => 29779
[last_post_username] => tooLongInEDA
[last_thread_id] => 20140
[last_thread_title] => US moves to bar Huawei, other Chinese telecoms from certifying wireless equipment
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[populated:protected] => 1
)
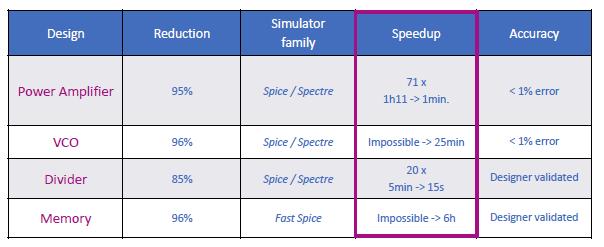
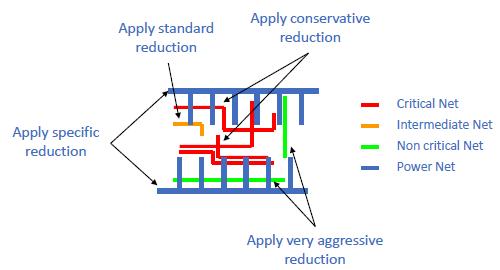
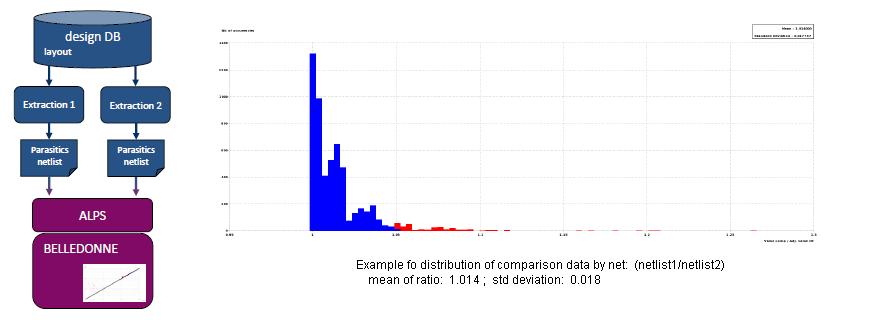




Comments
0 Replies to “It’s Time to Put Your Spice Netlists on a Diet”
You must register or log in to view/post comments.