
We’re putting the finishing touches on Chapter 9 of our upcoming book on ARM processors in mobile, this chapter looking at the evolution of Qualcomm. One of the things that made Qualcomm go was their innovative use of digital simulation. First, simulation proved out the Viterbi decoder (which Viterbi wasn’t convinced had a lot of practical value at first) prior to the principals forming Linkabit, then it proved out enhancements to CDMA technology (which was working in satellite programs) before Qualcomm launched into mobile. Simulation was used extensively to look at and solve problems like coding efficiency and power control for the near-far effect before committing algorithms to chips.
Back in the day, functional simulation was a competitive weapon, because not everyone was doing it. Now, functional simulation is almost a given in SoC design and verification. The same basic need exists – before committing a design to silicon, designers need to be sure it works correctly.
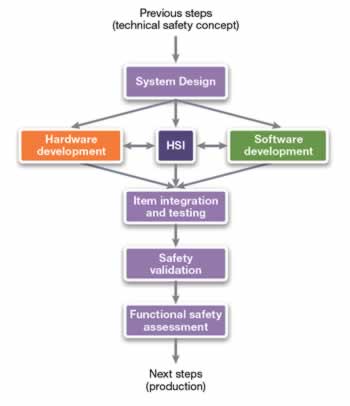
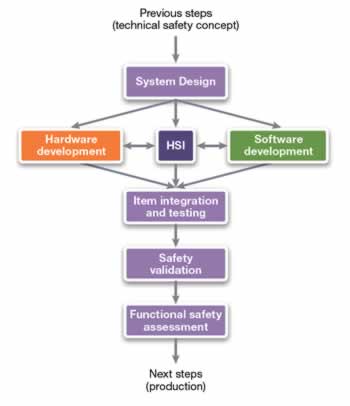
However, the objective is beginning to change driven by functional safety standards such as ISO 26262. Proving a design “works” to functional requirements in normal operation is merely a first step in the process.
As a new white paper from Synopsys puts it:
“Validating a safety critical system requires that the system is proven to work under the expected operational conditions and can also recover (within a time limit) to any fault occurring anywhere and at any time in the system.”
The automotive environment is complicated by the expense of the “plant”. Aerospace and automotive applications pioneered the use of hardware-in-the-loop strategies, combining expensive mechanical subsystems with electronics and software to create a working simulation. HIL handles the first part pretty well – proving an integrated system works under expected operational conditions.
State-of-the-art is moving to fault mode and effect analysis (FMEA). One of the tactics in FMEA is fault injection, which is useful for both corner cases that can be difficult to trigger, and outright failures that force a system to respond and contain a problem from cascading.
Hardware faults can be injected at the ECU-level by pin-forcing or external disturbance with EMI. However, there can be a multitude of issues internal to the ECU, and its SoC, that go unexercised. Similarly, software faults can be tossed into code, but they only exist where code normally touches hardware – memory and register locations. There is also the possibility that injecting faults in production software may have unexpected side effects on its functional response, defeating the purpose. Traditional simulation-based fault injection goes in at the RTL level, but is painfully slow, and difficult to use for timed faults with software interaction in complex scenarios.
Synopsys is postulating a methodology using virtual prototyping tools that accounts for electronic hardware, software, and physical plant components such as sensors and actuators. Virtual hardware in the loop, or vHIL, uses co-simulation and modeling to allow use of production software unmodified while still performing fault injection.
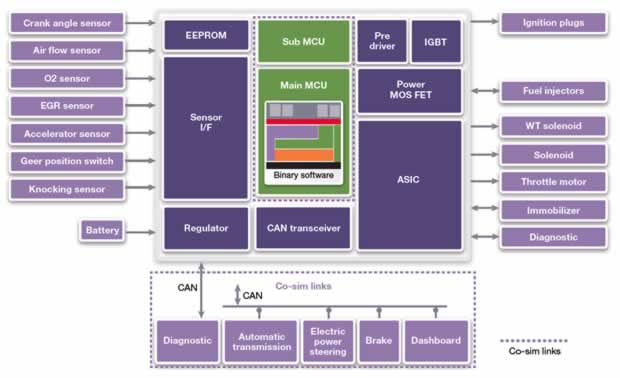
We took a brief look at this several months ago from a Synopsys webcast, but more details are in the first installment of a white paper series on the topic:
Is Your Automotive Software Robust Enough for Hardware Faults?
Part 1: Fault Mode and Effect Analysis Using Virtual Prototyping, Physical Modeling and Simulation
Their discussion on the types of faults and temporal aspects illustrates the shortcomings of traditional methods. They show how vHIL addresses these issues, and how other tools come into play for experimentation, analysis, and reporting.
Although this paper opens with a good discussion of the ISO 26262 context, it is clear the approach has implications beyond just automotive SoC design. I can see broader use of the approach for the IoT and medical applications, where the cost of failure can be much higher than the cost to simulate in advance. It seems high time we shift away from a CNTL-ALT-DEL mindset, where we just hit the reset button when it looks like something is messed up, to an environment where SoC failures are anticipated, modeled, and mitigated before they happen.
Just as Qualcomm rode simulation to its mobile greatness, a vHIL approach like Synopsys describes might be the next differentiator for semiconductor firms as applications become more safety critical.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.