
The traditional metrics for evaluating IP are performance, power, and area, commonly abbreviated as PPA. Viewed independently, PPA measures can be difficult to assess. As an example, design constraints that are purely based on performance, without concern for the associated power dissipation and circuit area, are increasingly rare. There is a related set of characteristics of importance, especially given the increasing integration of SoC circuitry associated with deep neural networks (DNN) – namely, the implementation energy and area efficiency, usually represented as a performance per watt measure and a performance per area measure.
The DNN implementation options commonly considered are: a software-programmed (general purpose) microprocessor core, a programmed graphics processing unit (GPU), a field-programmable gate array, and a hard-wired logic block. In 2002, Broderson and Zhang from UC-Berkeley published a Technical Report that described the efficiency of different options, targeting digital signal processing algorithms. [1]
The figure below (from a related ISSCC presentation) highlights the energy efficiency of various implementations, with a specific focus on multiprocessing/multi-core and DSP architectures that were emerging at that time:
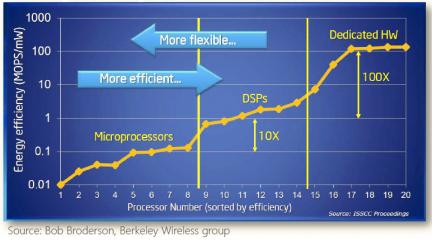
More recently, Microsoft published an assessment of the efficiency of implementation options for the unique workloads driving the need for “configurable” cloud services. [2] The cloud may provide unique compute resources for accelerating specific workloads, such as executing highly parallel algorithms and/or processing streaming data inputs. In this case, an FPGA option is also highlighted – the relative merits of an FPGA implementation are evident.

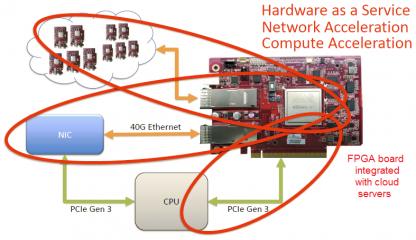
The conclusion presented by Microsoft is “specialization with FPGA’s is critical to the future cloud”. (FPGA’s are included in every Azure server, with a unique communication network interface that enables FPGA-to-FPGA messaging without CPU intervention, as depicted above.)
Back to DNN applications, the Architecture, Circuits, and Compilers Group at Harvard University recently presented their “SMIV” design at the recent Hot Chips Conference (link).
The purpose of this design tapeout was to provide hardware-based “PPA+E” metrics for deep neural network implementations, having integrated four major options:
- a programmable ARM Cortex-A53 core
- programmable accelerators
- an embedded FPGA block
- a hard-wired logic accelerator
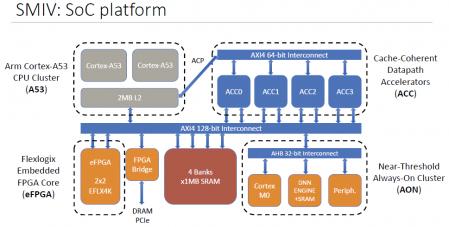
The Harvard design included programmable accelerators, with a unique interface to the L2 memory cache across an ARM AXI4 interface, in support of specific (fine-grained) algorithms. The hard-wired logic pursued a “near-threshold” circuit implementation, with specific focus on optimizing the power efficiency.
The evaluation data from the Harvard team are summarized below, for representative Deep Neural Network “kernels”.
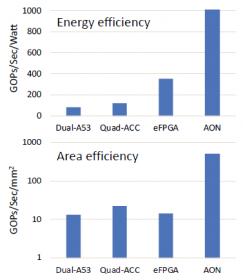
As with the Microsoft Azure conclusion, the efficiency results for the (embedded) FPGA option are extremely attractive.
I was intrigued by these results, and had the opportunity to ask Geoff Tate, Cheng Wang, and Abhijit Abhyankar of Flex Logix Technologies about their collaboration with the Harvard team. “Their design used a relatively small eFPGA array, with four eFLX tiles – two logic and two DSP-centric tiles.”, Geoff indicated. (For more details on the tile-based strategy for building eFPGA blocks, include the specific MAC functionality in the DSP tile, please refer to this earlier Semiwiki article – link.)
“The Harvard team tapeout used the original eFLX DSP tile design, where the MAC functionality is based on wide operators.”, Cheng indicated. Flex Logix has recently released an alternative tile design targeted for common neural network inference engines, with options for small coefficient bit widths (link).
“We are anticipating even greater efficiency with the use of embedded FPGA tiles specifically developed for AI applications. We are continuing to make engineering enhancements to engine and memory bandwidth tile features.”, Geoff forecasted.
Returning to the Harvard results above, although the PPA+E metrics for the attractive, a hard-wired ASIC-like approach is nonetheless still optimal for power efficiency (especially using a near-threshold library). What these figures don’t represent is an intangible characteristic – namely, flexibility of the deep neural network implementation. Inevitably, DNN algorithms for the inference engine are evolving for many applications, in pursuit of improved classification accuracy. In contrast to the eFPGA and processor core designs, a hard-wired logic network would not readily support the flexibility needed to make neural network changes to the depth and parameter set.
“Our customers consistently tell us that design flexibility associated with eFPGA DNN implementations is a critical requirement – that is part of our fundamental value proposition.”, Geoff highlighted.
The analysis data from the Harvard SMIV design contrasting processor, programmable logic, and hard-wired DNN implementations corroborates the high-level trends identified by Berkeley and Microsoft.
The traditional PPA (and licensing cost) criteria for evaluating IP needs to be expanded for the rapidly-evolving application space for a neural network inference engine, and must include (quantifiable) Efficiency and (more subjective)Flexibility. The capability to integrate embedded FPGA blocks into SoC’s offers a unique PPA+E+F combination – this promised to be an exciting technical area to track closely.
-chipguy
[1]Zhang, N., Broderson, R.W., “The cost of flexibility in systems on a chip design for signal processing applications.”, Technical Report, University of California-Berkeley, 2002.
[2]Putnam, A., “The Configurable Cloud — Accelerating Hyperscale Datacenter Services with FPGA’s”,2017 IEEE 33rd International Conference on Data Engineering (ICDE),
https://ieeexplore.ieee.org/document/7930129/ .




Comments
There are no comments yet.
You must register or log in to view/post comments.