

 While at the 54[SUP]th[/SUP] Design Automation Conference (DAC) I had the opportunity to talk with Ruben Molina, Product Management Director for Cadence’s Tempus static timing analysis (STA) tool. This was a good review of how the state-of-the-art for STA has evolved over the last couple decades. While the basic problem hasn’t changed much, the complexity of the problem has. Designers now deal with hundreds of millions of logic-gates, an explosion in the number of modes and corners to be analyzed as well as the added complexity of dealing with advanced process effects such as on-chip variation.
While at the 54[SUP]th[/SUP] Design Automation Conference (DAC) I had the opportunity to talk with Ruben Molina, Product Management Director for Cadence’s Tempus static timing analysis (STA) tool. This was a good review of how the state-of-the-art for STA has evolved over the last couple decades. While the basic problem hasn’t changed much, the complexity of the problem has. Designers now deal with hundreds of millions of logic-gates, an explosion in the number of modes and corners to be analyzed as well as the added complexity of dealing with advanced process effects such as on-chip variation.
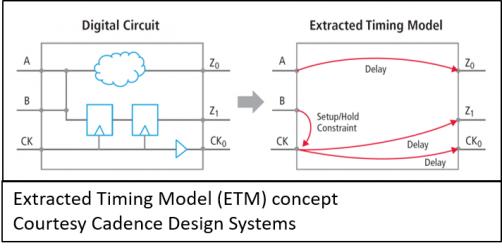 As design-size outpaced improvements in algorithm execution speed the industry went back to its trusted means of dealing with complexity – divide and conquer using hierarchy. For the last couple of decades, we have taught designers to cluster their logic into functional blocks which are then used and re-used throughout the design. A natural outgrowth of using design hierarchy was the use of ETMs (extracted timing models). The basic idea was to time the block at the gate level and then build an equivalent model with timing arcs for various input/output combinations. These models were faster and had smaller memory footprint but they suffered from many problems, most of which could be summed up under issues caused by lack of design context.
As design-size outpaced improvements in algorithm execution speed the industry went back to its trusted means of dealing with complexity – divide and conquer using hierarchy. For the last couple of decades, we have taught designers to cluster their logic into functional blocks which are then used and re-used throughout the design. A natural outgrowth of using design hierarchy was the use of ETMs (extracted timing models). The basic idea was to time the block at the gate level and then build an equivalent model with timing arcs for various input/output combinations. These models were faster and had smaller memory footprint but they suffered from many problems, most of which could be summed up under issues caused by lack of design context.
 The very thing that made hierarchy powerful (e.g. the ability to work on a piece of the design in isolation and then re-use it) was also its Achilles heel. The devil is the details as they say, and the details all come about when you put the design block into context, or in the case of IC designs, hundreds or thousands of different design contexts. A notable factor that made ETMs not so useful is that at smaller process nodes wiring delay and signal integrity (SI) become dominant and are context sensitive, something that the ETMs did not comprehend well.
The very thing that made hierarchy powerful (e.g. the ability to work on a piece of the design in isolation and then re-use it) was also its Achilles heel. The devil is the details as they say, and the details all come about when you put the design block into context, or in the case of IC designs, hundreds or thousands of different design contexts. A notable factor that made ETMs not so useful is that at smaller process nodes wiring delay and signal integrity (SI) become dominant and are context sensitive, something that the ETMs did not comprehend well.
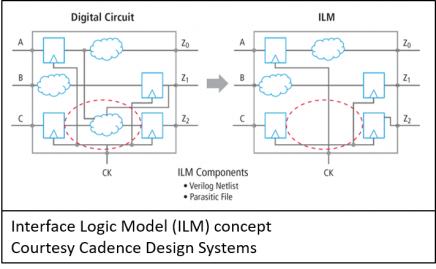
The industry next moved to ILMs (interface logic models). The idea here was to keep the hierarchical block’s interface logic and to remove the rest of the register-to-register logic inside the block. These models were more accurate than ETMs as they delivered the same timing for interface paths to the block as did a flat analysis. You could also merge the ILM netlist with some of the contextual impacts (parasitics, SI effects) at least for the interface logic.
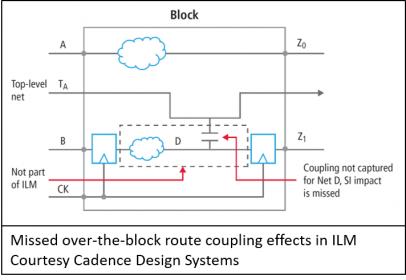
ILMs still however lacked knowledge of over-the-block routing and its associated SI impacts and one still had to deal with creating a significant number of unique models for block instances to correctly handle multi-mode, multi-corner (MMMC) analysis. Additionally, things like common path pessimism removal (CPPR) from the top-level required special handling.
In the end, sign-off STA was still best done with a full flat analysis to handle all the important contextual information (logical, electrical and physical). The problem then, was back to how to get the compute time and memory footprint down while also enabling teams of designers to be able to work in parallel on a flat design.
Enter Cadence with Tempus. The Tempus team attacked the problem on two levels. From the beginning, the team developed a novel way of automatically breaking the design down into semi-autonomous cones of logic each of which could be run on different threads (MTTA – multi-threaded timing analysis) and across multiple machines (DSTA – distributed static timing analysis). As part of this, they worked out methods for inter-client communications that enabled the tool to pass important information like timing windows between associated cones of logic.
To be clear, Tempus is no slouch. Per Ruben, the raw speed of Tempus is quite amazing, allowing you to effectively run blocks of up to 40 million cells in a single client. Take that and distribute it and you can see how they can effectively handle very large designs. This turned out to be the answer for the first question. The second question however remained about how to enable teams of designers to work in parallel on flat data.
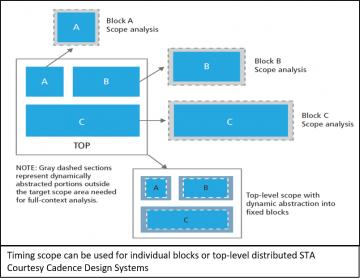
As it turns out, the first breakthrough led to the second. Once Tempus could automatically identify cones of logic that were dependent upon each other for accurate timing analysis, it was also realized that the inverse was true as well. Tempus knows which blocks of logic can be safely ignored for any selected block that is to be timed! Translated, that means Tempus can automatically carve out just enough logic around a selected block to ensure an accurate analysis without having to time the entire netlist.
This is essentially what is being done automatically for MTTA and DSTA, however now the Tempus team could enable designers to use this to their advantage. Designers could use the tool to semi-automatically carve the design up into blocks that could be given to multiple designers to work in parallel. In short, a new kind of hierarchy was being enabled whereby top-level constraints could be first handed to block implementers. Once implemented, the blocks could then be passed back to the top-level for assembly and routing. Once context is set, blocks could then be passed back down for final timing optimization. Of course, it’s never that simple but now designers had a way to iterate blocks with the top-level to converge on timing. Second problem solved!
The beauty of this flow is that the same timing scripts, constraints and use-model for flat timing analysis can be used for the top-level and block-level optimizations. All reporting commands operate in the same way as no tricks are required to handle CPPR and MMMC as all data for the flat run is present during top-level and block-level optimization. Scope-based analysis can be run in parallel either by multiple designers or through Tempus distributed processing. The flow provides a significant speed-up in runtime over full flat optimization and as a bonus, DSTA can be used to make parallel runs for MMMC analysis.
I really like what the Tempus team has done here. First, they improved overall tool performance without sacrificing accuracy. Second, they automated the book keeping part of the tool so that designers can stay focused on design tasks instead of wasting time manipulating data to enable the tool. Lastly, the tool is still flexible enough to allow designers to manage their own design methodology to iterate the design to timing closure. A job well done!
See Also:
Tempus Timing Sign-off Solution web page
Hierarchical Timing Analysis White Paper




Comments
2 Replies to “Cadence’s Tempus – New Hierarchical Approach for Static Timing Analysis”
You must register or log in to view/post comments.