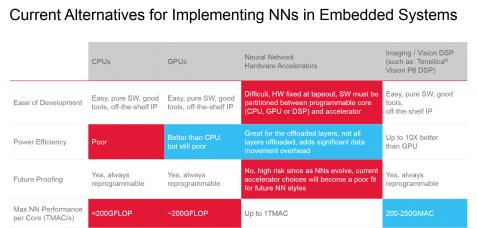

If you read an article dealing with Convolutional Neural Network (CNN), you will probably hear about the battle between CPU and GPU, both off-the-shelf standard product. Addressing CNN processing needs with standard CPU or GPU is like having to sink a screw when you only have a hammer or a monkey wrench available. You can dissert for a while and finally come to the conclusion that the hammer is better suited than the monkey wrench, or decide that the GPU is better than the CPU (which is probably true). At least if you don’t know the screwdriver…
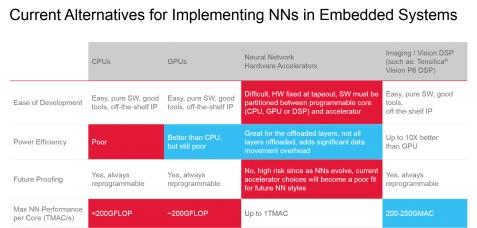
Now, just imagine that you discover the imagine/vision DSP (such as Tensilica Vision P6 DSP IP from Cadence) and integrate this new option to the comparison chart, like done in the above table. The CPU and GPU options are good in term of “Ease of Development” and “Future Proofing” criteria, but the DSP core as well. When it comes to “Power Efficiency”, the GPU based solution appears to be better than CPU, and this will probably be the conclusion of the above-mentioned article. With no screwdriver available, it’s probably more convenient to use a hammer to sink the screw! But if you compare the power efficiency of the DSP based solution with the GPU, you realize that the DSP core can be up to 10X better.
Cadence has also compared the pure DSP solution with the approach mixing a DSP (or CPU or GPU) and dedicated hardware accelerators (HA), which may seem attractive, at it allows to offload very precise tasks. In the case of CNN algorithms, the tasks offloaded to the HA are only the convolution layers, as all others neural network (NN) layers are run on the imaging DSP, control CPU or GPU. This architecture lead to excessive data movement between two processing elements (NN and main DSP/CPU/GPU). These data movement are degrading the global power efficiency, even if the accelerated convolutional layers are showing good power efficiency in stand-alone.
But the main drawback is linked with the CNN algorithm development trends. Even if the realistic semiconductor based solution for CNN are pretty recent (2012), at that time Alexnet was the preferred algorithm, requiring 700k + MACS per image. In less than 4 years, Inception and ResNet have been introduced and the computational requirements have jumped to 5.7M (Inception V3) or even 11M MACS per image for ResNet-152. This means that you would have to drop any hardware accelerator based solution designed to support Alexnet.
Moreover, network architectures are changing regularly, as Inception V3 and ResNet are based on smaller convolution that Alexnet. If you select an inference hardware platform in 2017, the product will be shipping in 2019 or 2020. It will have to achieve low-power efficiency (and DSP + HA does), but also stay flexible… and only a pure DSP based embedded solution can make it.
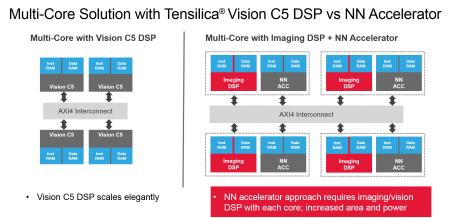
The problem becomes even worse when you need to scale the selected solution, for example to support Surveillance or semi-autonomous Automotive application requiring about 1 TMAC/s, and running a couple of neural networks all the time. If you want to address (toward) autonomous Automotive, the processing requirement moves by one order of magnitude (10 TMAC/s) and several NN have to run all the time.
Cadence proposes a multi-core solution based on Vision C5 DSP, each core being a complete, standalone solution that runs all layers of NN (convolution, fully connected, normalization, polling…) and this solution scales elegantly compared with the multi-core with Imaging DSP + HA. In fact NN accelerator requires to implement a Vision/Imaging DSP with each core, as shown on the above picture.
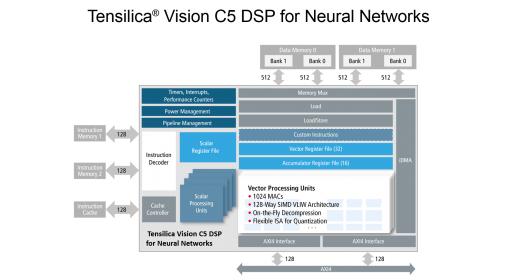
The Tensilica Vision C5 DSP for Neural Networks is a dedicated, NN-optimized DSP core (general purpose and programmable), architected for multi-processor design and scaling to multi-TMAC/s, not a “hardware accelerator” paired with a vision DSP. That’s why it’s not only a power efficient solution, but also a flexible architecture, well suited for CNN algorithms needs: increasing computational requirements and fast evolving networks architecture.
By Eric Esteve fromIPnest




Comments
2 Replies to “CPU, GPU, H/W Accelerator or DSP to Best Address CNN Algorithms?”
You must register or log in to view/post comments.