
When I first saw that Rob Knoth (Product Director at Cadence) had proposed this topic as a subject for a blog, my reaction was “well, how accurate can that be?” I’ve been around the power business for a while, so I should know better. It’s interesting that I jumped straight to that one metric for QoR; I suspect many others will do the same. I guess none of us is as objective as we like to think we are.
Here’s why. It is generally agreed that power estimation at the (implementation) gate-level can get within 5% of power measured on silicon – with caveats, but let’s use that as a working number. This has great value, but it’s primarily signoff value. If estimates are outside expectations, gate-level analysis won’t provide much help on where to make fixes. That’s why power estimation at RTL has become popular. Absolute accuracy tends to fall within 15% of gate-level which may seem less appealing, but relative accuracy (design rev A is better than design rev B) is better, micro-architecture experiments (clock-gating, power-gating, etc) can be performed quickly using the estimates as a metric, and significant power savings can be found at this level – much larger than anything possible at implementation. Point being, if you move up a level of abstraction, accuracy drops but payback jumps significantly and you can iterate much more quickly on experiments.
The same reasoning applies when you move up to the system (in this case System-C) level since, as is well known, power-saving techniques have increasing impact as you move up the stack from implementation to application software. In this case, at RTL you can tune micro-architecture, at System-C you can tune architecture, with a bigger potential payback.
Of course, that only helps if you are able to optimize the design at the system level. System-C is still on the fringes of “traditional” designer consciousness in the Bay Area though that is starting to change with the rise of design in system houses and it remains popular in Europe and Asia, especially where there maybe isn’t so much legacy investment in RTL methodologies and training. Some groups in the larger semiconductor companies are also getting in on the action. You too might start to understand the appeal as you read the rest of this blog.
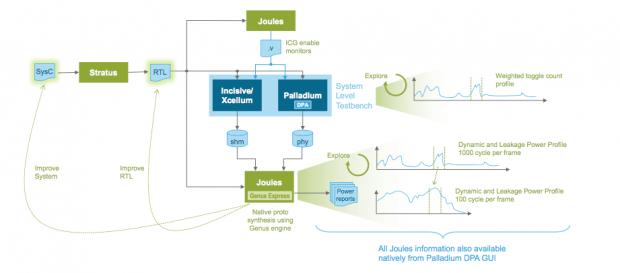
The bulk of this system power estimation flow is based on RTL power-estimation, using Palladium or Incisive/Xcelium as the activity-modeling workhorse and Joules as the power-estimation engine. That answers one part of the accuracy question – in principle this flow should be as accurate as an RTL estimation flow, as long as you don’t mess with the generated RTL (if you do mess with the RTL, you can always re-run power estimation on that RTL). Not messing with the RTL (taking HLS output direct to implementation) seems to be a trend among designers using System-C, suggesting accuracy for this flow should be close to RTL accuracy.
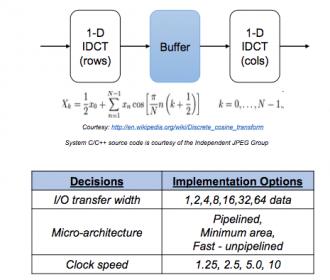
Cadence illustrate use of this flow using design of a 2-dimensional IDCT for which they want to explore various architectural options. In this flow, they’re using Stratus to synthesize System-C and flow automation starts from this point using Tcl scripts which also build the appropriate Makefiles to drive simulation or emulation and power estimation as needed.
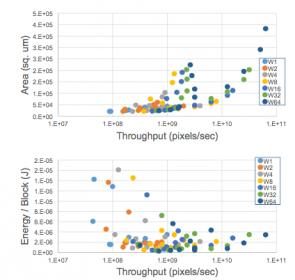
Where this gets impressive is the range of options they were able to explore. They looked at 84 different architecture options covering differing word-widths, trading-off sharing versus parallelism, storage as memory versus flip-flops and multiple other options. This analysis was automated through scripting from Stratus, so once setup, they just pushed the button, sat back and watched the results roll in. The setup takes work, but once in place it becomes relatively easy to extend analysis to cover more options.
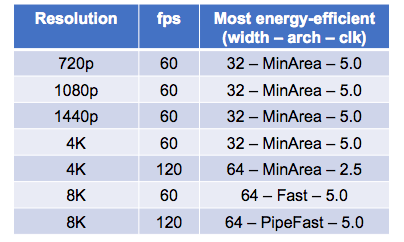
At that point, it’s trivial to pick off best architecture options. Looking at performance, energy and area, they found that best architecture can vary quite significantly as these targets change. Perhaps unsurprising, but getting from a hand-waving observation to figuring out the optimum architecture for a target application is going to be a lot of work unless you can use a flow like this.
That was an internal experiment, however Cadence also cited a real case study for a satellite application where an existing C/C++ implementation on a DSP had to be migrated to RTL. Previous attempts were based on hand-developed RTL, starting from the C/C++ code. Switching over to the System-C approach, the design team was able to get to first RTL in 1 week and an optimized design in 5 weeks, exploring multiple architectural options. Area was 28% smaller and power was 4X lower than for the hand-coded version. Purely through optimizing the architecture. As easy Moore’s law cost/performance gains evaporate, it makes you wonder how much architectural wiggle room may be untapped in other designs. And whether this might be a motivator to migrate more block design to System-C. Food for thought.
You can read a more detailed paper on the internal experiments HERE.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.