

One serious challenge to the early promise of accelerating verification through emulation was that, while in theory the emulator could run very fast, options for driving and responding to that fast model were less than ideal. You could use in-circuit emulation (ICE), connecting the emulation to real hardware and allowing you to run fast (with a little help in synchronizing rates between the emulation and the external hardware). But these setups took time, often considerable time, and had poor reliability; at least one connection would go bad every few hours and could take hours to track down.

Alternatively, you could connect to a (software-based) simulator testbench, running on a PC, but that dragged overall performance down to little better than running the whole testbench + DUT (device under test) simulation on the PC. For non-experts in the domain, testbenches mostly run on a PC rather than the emulator, because emulators are designed to deal with synthesizable models, while most testbenches contain logic too complex to be synthesizable. Also emulators are expensive, so even if a testbench can be made synthesizable, there’s a tradeoff between cost and speed.
ICE for all its problems was the only usable option but was limited by cost and value in cases where setup might take nearly as much time as getting first silicon samples. More recently, ICE has improved dramatically in usability and reliability and remains popular for live in-circuit testing. Approaches to software-based testing have also improved dramatically and are also popular where virtualized testing is considered a benefit, and that’s the subject of this blog. (I should note in passing that there are strong and differing views among emulation experts on the relative merits of virtual and ICE-based approaches. I’ll leave that debate to the protagonists.)
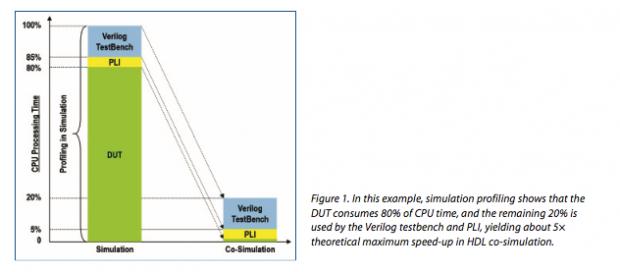 There are two primary reasons that simulation-based testbenches are slow – low level (down to signal-level, cycle-accurate) modeling in the testbench and massive amounts of signal-level communication between the testbench and the DUT. Back in the dawn of simulation time, the first problem wasn’t a big deal. Most of the simulation activity was in the DUT and the testbench accounted for a small overhead. But emulation (in principle) reduces DUT time by several orders of magnitude, so time spent in the testbench (and PLI interfaces) becomes dominant. Overall, you get some speed-up but it falls far short of those orders of magnitude you expected.
There are two primary reasons that simulation-based testbenches are slow – low level (down to signal-level, cycle-accurate) modeling in the testbench and massive amounts of signal-level communication between the testbench and the DUT. Back in the dawn of simulation time, the first problem wasn’t a big deal. Most of the simulation activity was in the DUT and the testbench accounted for a small overhead. But emulation (in principle) reduces DUT time by several orders of magnitude, so time spent in the testbench (and PLI interfaces) becomes dominant. Overall, you get some speed-up but it falls far short of those orders of magnitude you expected.
This problem becomes much worse when you think of the testbenches we build today. These are much more complex thanks to high levels of behavioral modeling and assertion/coverage properties. Now it is common to expect 50-90% of activity in the testbench (that’s why debugging testbenches has become so important); as a result traditional approaches to co-simulation with an emulator show hardly any improvement over pure simulation speeds.
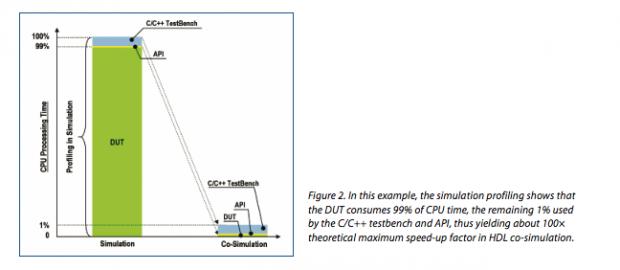 One way to fix this problem is to move up the level of abstraction for the testbench to C/C++. This is a popular trend, especially in software-driven/system level testing where translating tests to SV/UVM may become challenging and arguably redundant. (SV/UVM still plays a role as a bridge to emulation.) Now testbench overhead can drop down to a very small percentage, delivering much more of that promised emulation speedup to total verification performance.
One way to fix this problem is to move up the level of abstraction for the testbench to C/C++. This is a popular trend, especially in software-driven/system level testing where translating tests to SV/UVM may become challenging and arguably redundant. (SV/UVM still plays a role as a bridge to emulation.) Now testbench overhead can drop down to a very small percentage, delivering much more of that promised emulation speedup to total verification performance.
But you still must deal with all that signal communication between testbench and emulator. Now the botteleneck is defined by thousands of signals, each demanding synchronized handling of cycle-accurate state changes. That signal interface complexity also must be abstracted to get maximum return from the testbench/emulator linkage. That’s where the second important innovation comes in – a transaction-based interface. Instead of communicating signal changes, you communicate multi-cycle transactions; this alone could allow for some level of speed-up.
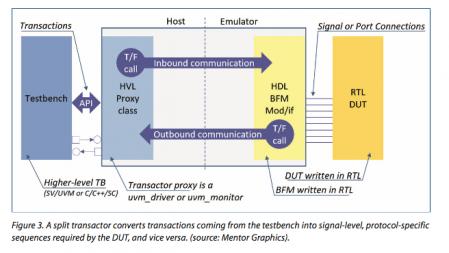
But what really makes the transaction-based interface fly is a clever way to implement communication through the Standard Co-Emulation Modeling Interface (SCE-MI). SCE-MI is an Accellera-defined standard based on the Direct Programming Interface (DPI) extension to the SV standard. This defines a mechanism to communicate directly and portably (without PLI) between an abstracted testbench and an emulator.
The clever part is splitting communication into two functions, one running on the emulator and the other on the PC. On the emulator, you have a synthesizable component assembling and disassembling transactions. On one side, it’s communicating with all those signals from the DUT and can run at emulator speed because it’s synthesized into emulator function primitives. On the other side, it communicates transactions to a proxy function running on the PC.
Now you have fast performance on the emulator, fast (because greatly compressed) communication between PC and emulator, and fast performance in the testbench. All of which makes it possible to rise closer to the theoretical performance that the emulator can offer. It took a bunch of work and a couple of standards but the payback is obvious. What’s more, tests you build should be portable across emulation platforms. Pretty impressive. Mentor has a white-paper which gives more details.
Share this post via:



Comments
0 Replies to “The Rise of Transaction-Based Emulation”
You must register or log in to view/post comments.