Threads
XF\Mvc\Entity\ArrayCollection Object
(
[entities:protected] => Array
(
[18682] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 51
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 18682
[node_id] => 2
[title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[reply_count] => 41
[view_count] => 9889
[user_id] => 323155
[username] => Maximus
[post_date] => 1693550522
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 63670
[first_post_reaction_score] => 3
[first_post_reactions] => {"1":3}
[last_post_date] => 1713565688
[last_post_id] => 69457
[last_post_user_id] => 1305
[last_post_username] => KevinK
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 323155
[username] => Maximus
[username_date] => 0
[username_date_visible] => 0
[email] => smileeveryday@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => Asia/Hong_Kong
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 82
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1675392931
[last_activity] => 1713515447
[last_summary_email_date] => 1675392931
[trophy_points] => 18
[alerts_unviewed] => 3
[alerts_unread] => 3
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 77
[warning_points] => 0
[is_staff] => 0
[secret_key] => SApIO3hYIRzq0CgVS0eun_zG8PWod-3y
[privacy_policy_accepted] => 1675392931
[terms_accepted] => 1675392931
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20058] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20058
[node_id] => 2
[title] => TSMC Q1 2024 Discussion
[reply_count] => 26
[view_count] => 1126
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713436946
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69402
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1713548865
[last_post_id] => 69449
[last_post_user_id] => 138292
[last_post_username] => MKWVentures
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20061] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 59
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20061
[node_id] => 2
[title] => Drone Submarines and Ocean development, A semi market of staggering size
[reply_count] => 2
[view_count] => 170
[user_id] => 10499
[username] => Arthur Hanson
[post_date] => 1713531600
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69440
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1713544997
[last_post_id] => 69447
[last_post_user_id] => 38642
[last_post_username] => VCT
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 10499
[username] => Arthur Hanson
[username_date] => 0
[username_date_visible] => 0
[email] => a-j-hanson@att.net
[custom_title] =>
[language_id] => 1
[style_id] => 1
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 2962
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1366028460
[last_activity] => 1713530972
[last_summary_email_date] => 1606051785
[trophy_points] => 83
[alerts_unviewed] => 6
[alerts_unread] => 6
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 340
[warning_points] => 0
[is_staff] => 0
[secret_key] => ta_8_Pj20m6PDO6RnrGK-VnSP_vyhP_m
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20062] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 63
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20062
[node_id] => 2
[title] => Timing for TSMC Wafer Orders
[reply_count] => 0
[view_count] => 144
[user_id] => 36490
[username] => fansink
[post_date] => 1713539716
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69442
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1713539716
[last_post_id] => 69442
[last_post_user_id] => 36490
[last_post_username] => fansink
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 60
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 36490
[username] => fansink
[username_date] => 1633797241
[username_date_visible] => 1633786579
[email] => dt@novelconceptsinc.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 179
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1607181097
[last_activity] => 1713542441
[last_summary_email_date] =>
[trophy_points] => 28
[alerts_unviewed] => 1
[alerts_unread] => 1
[avatar_date] => 1633786654
[avatar_width] => 384
[avatar_height] => 384
[avatar_highdpi] => 1
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 75
[warning_points] => 0
[is_staff] => 0
[secret_key] => JnrZQ1Uify4Q71rQ2GE1O9d7OVlT2ojg
[privacy_policy_accepted] => 1607181097
[terms_accepted] => 1607181097
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20059] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 67
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20059
[node_id] => 2
[title] => Intel is industry’s first mover on High NA EUV lithography system.
[reply_count] => 11
[view_count] => 743
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713453303
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69412
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1713515074
[last_post_id] => 69437
[last_post_user_id] => 35301
[last_post_username] => Xebec
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20060] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 71
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20060
[node_id] => 2
[title] => Micron set to get $6.1 bln in chip grants from US
[reply_count] => 2
[view_count] => 257
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713457899
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69417
[first_post_reaction_score] => 2
[first_post_reactions] => {"1":1,"2":1}
[last_post_date] => 1713483584
[last_post_id] => 69427
[last_post_user_id] => 170880
[last_post_username] => nghanayem
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20056] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 75
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20056
[node_id] => 2
[title] => 5 things you should know about High NA EUV lithography
[reply_count] => 10
[view_count] => 1296
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713361658
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69370
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1713480271
[last_post_id] => 69424
[last_post_user_id] => 8322
[last_post_username] => hskuo
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20051] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 79
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20051
[node_id] => 2
[title] => A new generation is uncovering the tiny doodles left by engineers on old microchips
[reply_count] => 2
[view_count] => 441
[user_id] => 14042
[username] => hist78
[post_date] => 1713273601
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69343
[first_post_reaction_score] => 3
[first_post_reactions] => {"1":3}
[last_post_date] => 1713410935
[last_post_id] => 69397
[last_post_user_id] => 20231
[last_post_username] => Barnsley
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 76
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 14042
[username] => hist78
[username_date] => 0
[username_date_visible] => 0
[email] => ckckhcdc@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 0
[activity_visible] => 0
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 2532
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1389969050
[last_activity] => 1713577153
[last_summary_email_date] => 1605978520
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 2
[avatar_date] => 1604959511
[avatar_width] => 807
[avatar_height] => 384
[avatar_highdpi] => 1
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 1641
[warning_points] => 0
[is_staff] => 0
[secret_key] => 2YRSnPrl4fVQSdv3R6uqHxqi6BDQOXve
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20054] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 83
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20054
[node_id] => 2
[title] => A question regards to the semiconductor value chain
[reply_count] => 10
[view_count] => 547
[user_id] => 32033
[username] => jm820428
[post_date] => 1713340097
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69362
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1713409181
[last_post_id] => 69396
[last_post_user_id] => 32033
[last_post_username] => jm820428
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 80
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 32033
[username] => jm820428
[username_date] => 0
[username_date_visible] => 0
[email] => jm820428b@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => Asia/Hong_Kong
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 11
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1567331761
[last_activity] => 1713409181
[last_summary_email_date] => 1712326810
[trophy_points] => 3
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 7
[warning_points] => 0
[is_staff] => 0
[secret_key] => bp0KQFmJ_lKCDFrvLXNBQcAlw2hOikoo
[privacy_policy_accepted] => 1567331761
[terms_accepted] => 1567331761
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20031] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 87
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20031
[node_id] => 2
[title] => Japan chipmaker Rapidus opens arm in Nvidia's backyard from Nikkei Asia
[reply_count] => 16
[view_count] => 1259
[user_id] => 8322
[username] => hskuo
[post_date] => 1713149424
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69306
[first_post_reaction_score] => 3
[first_post_reactions] => {"1":3}
[last_post_date] => 1713396234
[last_post_id] => 69392
[last_post_user_id] => 322214
[last_post_username] => Mooredaddy
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 84
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 8322
[username] => hskuo
[username_date] => 0
[username_date_visible] => 0
[email] => h_s_kuo@yahoo.com.tw
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => Asia/Singapore
[visible] => 0
[activity_visible] => 0
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 313
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1353653082
[last_activity] => 1713563893
[last_summary_email_date] =>
[trophy_points] => 63
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 262
[warning_points] => 0
[is_staff] => 0
[secret_key] => dmSCPzj7nJ30LudrsWqXuEY0wtWsm9Z5
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20057] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 91
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20057
[node_id] => 2
[title] => Semiconductor equipment maker ASML ships second 'High NA' EUV machine
[reply_count] => 1
[view_count] => 571
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713364253
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69374
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1713366217
[last_post_id] => 69381
[last_post_user_id] => 5185
[last_post_username] => Fred Chen
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[19747] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 95
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 19747
[node_id] => 2
[title] => imec study of EUV stochastic defects in wafer yield at SPIE 2024
[reply_count] => 5
[view_count] => 1194
[user_id] => 5185
[username] => Fred Chen
[post_date] => 1709376517
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 68076
[first_post_reaction_score] => 3
[first_post_reactions] => {"1":3}
[last_post_date] => 1713365052
[last_post_id] => 69378
[last_post_user_id] => 5185
[last_post_username] => Fred Chen
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 92
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5185
[username] => Fred Chen
[username_date] => 0
[username_date_visible] => 0
[email] => chen.t.fred@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 4
[secondary_group_ids] =>
[display_style_group_id] => 4
[permission_combination_id] => 92
[message_count] => 1706
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1333032401
[last_activity] => 1713536966
[last_summary_email_date] => 1605940563
[trophy_points] => 113
[alerts_unviewed] => 2
[alerts_unread] => 3
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 812
[warning_points] => 0
[is_staff] => 0
[secret_key] => 5m-bZq0HRSi9VA-96QONHJeevdQas5S8
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20053] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 99
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20053
[node_id] => 2
[title] => The state of the Foundry market before TSMC reports
[reply_count] => 7
[view_count] => 847
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713280970
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69347
[first_post_reaction_score] => 6
[first_post_reactions] => {"1":6}
[last_post_date] => 1713364330
[last_post_id] => 69375
[last_post_user_id] => 138292
[last_post_username] => MKWVentures
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20055] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 103
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20055
[node_id] => 2
[title] => Applied Materials could abandon $4bn US R&D project
[reply_count] => 3
[view_count] => 314
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713358928
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69368
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1713363761
[last_post_id] => 69373
[last_post_user_id] => 20231
[last_post_username] => Barnsley
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20010] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 107
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20010
[node_id] => 2
[title] => China to become world's largest source of IC wafer capacity by 2026 - Knometa Research
[reply_count] => 10
[view_count] => 852
[user_id] => 36640
[username] => soAsian
[post_date] => 1712762450
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69181
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1713360761
[last_post_id] => 69369
[last_post_user_id] => 36448
[last_post_username] => Paul2
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 104
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 36640
[username] => soAsian
[username_date] => 0
[username_date_visible] => 0
[email] => jackmtsai@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/Chicago
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 157
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1608139716
[last_activity] => 1713571126
[last_summary_email_date] => 1705155721
[trophy_points] => 28
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 77
[warning_points] => 0
[is_staff] => 0
[secret_key] => 2oKeCTFkGUpMro5tcmj7WaY9HksB13Kw
[privacy_policy_accepted] => 1608139716
[terms_accepted] => 1608139716
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20052] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 111
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20052
[node_id] => 2
[title] => Startup Rivos raises $250 million to develop RISC-V AI chips
[reply_count] => 3
[view_count] => 384
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713279444
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69345
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1713320104
[last_post_id] => 69361
[last_post_user_id] => 38697
[last_post_username] => blueone
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20032] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 115
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20032
[node_id] => 2
[title] => Biden-Harris Administration Announces Preliminary Terms with Samsung Electronics to Establish Leading-Edge Semiconductor Ecosystem in Central Texas
[reply_count] => 10
[view_count] => 883
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713186549
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69307
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1713316260
[last_post_id] => 69359
[last_post_user_id] => 322214
[last_post_username] => Mooredaddy
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20036] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 119
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20036
[node_id] => 2
[title] => Inside Micron Taiwan’s Semiconductor Factory
[reply_count] => 1
[view_count] => 436
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713191305
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69312
[first_post_reaction_score] => 2
[first_post_reactions] => {"1":2}
[last_post_date] => 1713268799
[last_post_id] => 69342
[last_post_user_id] => 10499
[last_post_username] => Arthur Hanson
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20042] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 123
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20042
[node_id] => 2
[title] => Updates: Intel’s 10 Largest Construction Projects
[reply_count] => 0
[view_count] => 425
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713220978
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69325
[first_post_reaction_score] => 4
[first_post_reactions] => {"1":4}
[last_post_date] => 1713220978
[last_post_id] => 69325
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[20035] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 127
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 20035
[node_id] => 2
[title] => Don’t Count Samsung Out in the AI Memory Stakes
[reply_count] => 1
[view_count] => 413
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1713190055
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 69311
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1713203844
[last_post_id] => 69319
[last_post_user_id] => 14042
[last_post_username] => hist78
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 11304
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1713565764
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 0
[alerts_unread] => 22
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 3364
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 5711
[message_count] => 35303
[last_post_id] => 69457
[last_post_date] => 1713565688
[last_post_user_id] => 1305
[last_post_username] => KevinK
[last_thread_id] => 18682
[last_thread_title] => Kirin 9000s Analysis: Should be Made by SMIC's N+2 Process
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[populated:protected] => 1
)
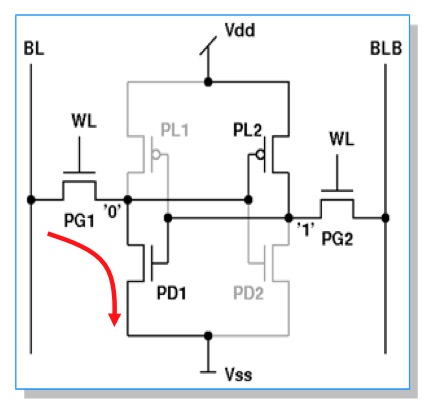

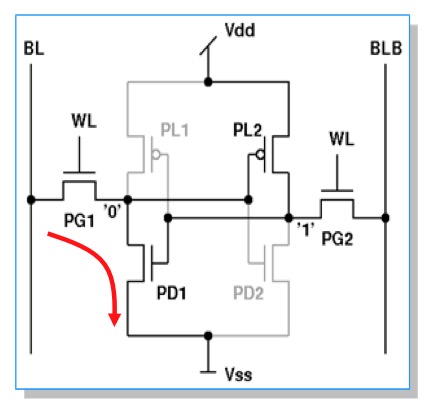
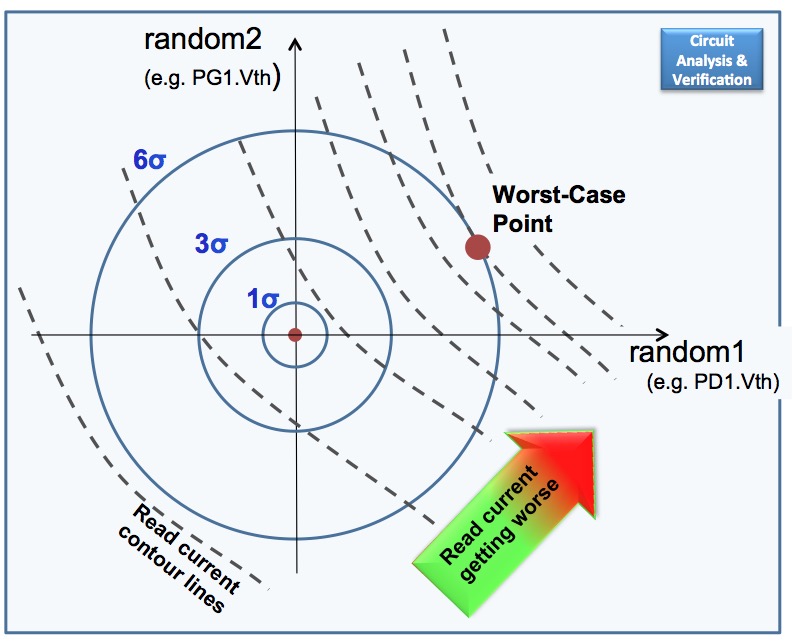
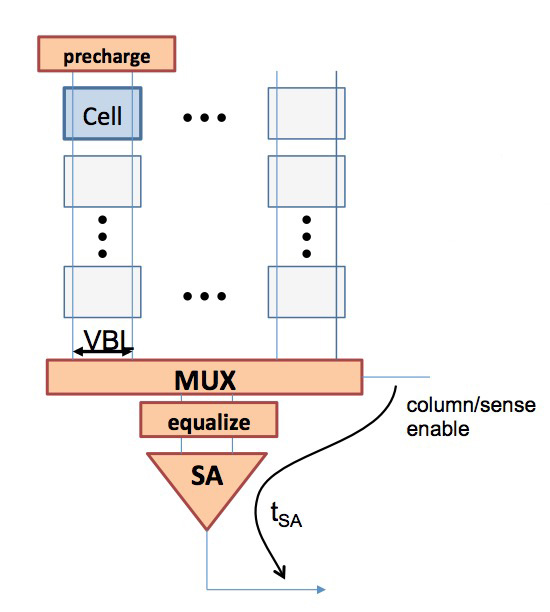
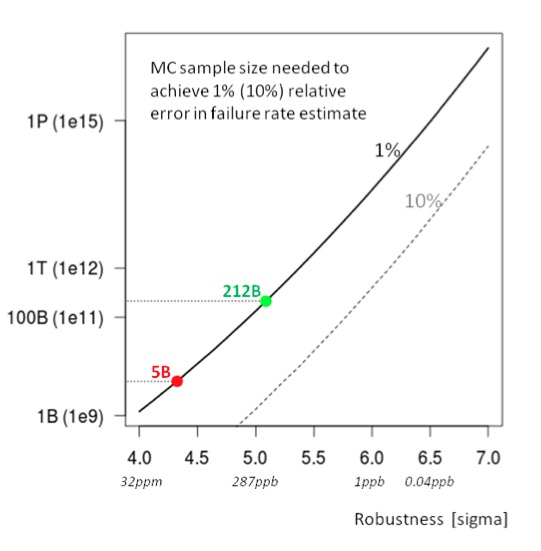
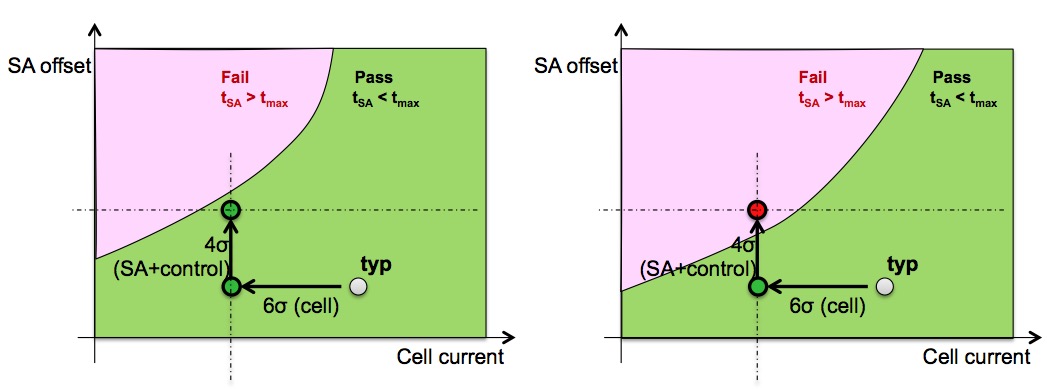
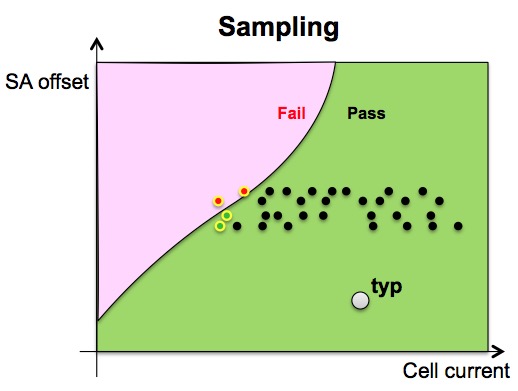
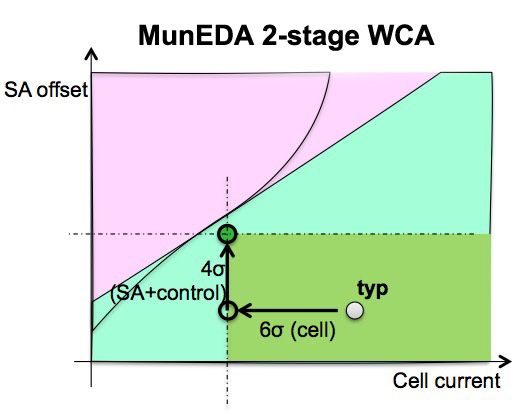
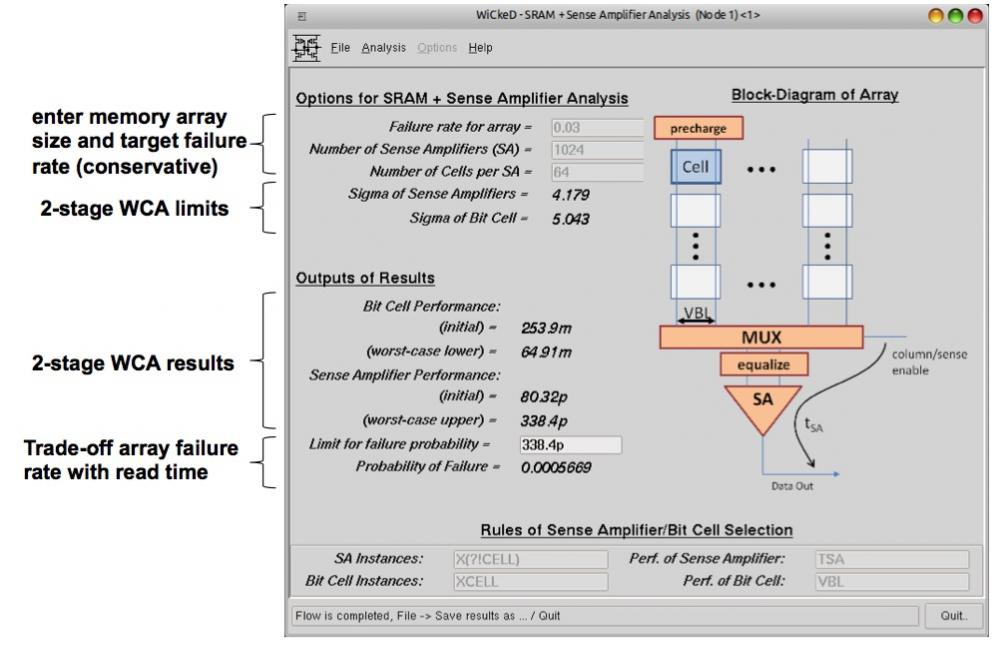
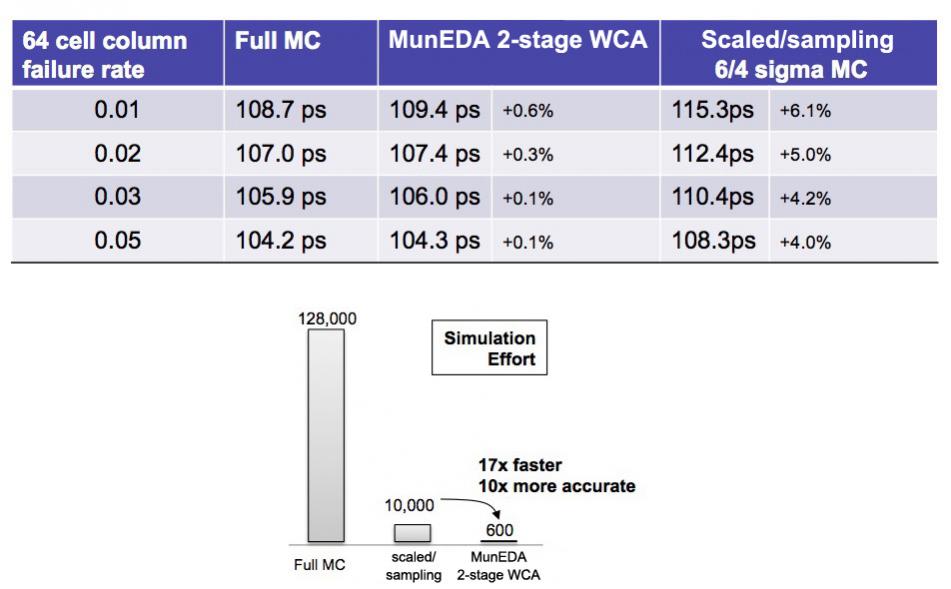




Comments
0 Replies to “Optimizing SRAM IP for Yield and Reliability”
You must register or log in to view/post comments.