
Like Guiness dark beer, competition is good for you! I mean good for end user, as it pushes DSP IP supplier to provide ever better solution. I am not talking about me-to type of competition, like that we have seen in the past with IBM trying to displace TI at Nokia, by offering a LEAD (DSP IP core from TI used in every NOKIA wireless phone at that time) clone, it happened in the 90’s… MUST (Multicore System Technology) does not try to mimic any competitor solution: this multi-core system based on CEVA-XC 4000 family includes Data Traffic Management (DTM), Data cache & cache coherency, vector floating point instruction set and high performance FPU, as well as a port-folio of ultra-low power co-processor for wireless modems.
The latest Modem specifications in Wireless terminal are very challenging:
- Strict latency requirements are defined by the standard: the Multiple DSP processors and co-processors must be fully synchronized with minimal overhead
- Supporting true multi-mode modem design: require using ultra low-power Co-processors allowing multi-mode support (LTE-A, HSPA+, WiFi, etc.)
- System interconnect should support very high bandwidth: data management has to be integrated into the DSP IP solution
- Size of modem is dominated by memory buffers: Smart architecture can reduce up to 30% memory size requirements
We better understand why a DSP IP vendor like CEVA had to move from a DSP core supplier to a technology supplier, as illustrated by MUST solution above.
MUST integrate Data Traffic Manager (DTM) and an Advanced System Interconnect. I love the above picture illustrating DTM in action, with three cases, as I feel I can, probably for the first time, understand how it works:
- First case (Top): The HW accelerator integrated buffer being FULL, send a flag to the DTM, the DTM stop sending data from the CEVA-XC associated buffer
- Second case (middle): CEVA-XC associated buffer is EMPTY, send a flag to the TCE, the TCE can start working
- Third case (bottom): CEVA-XC associated buffer is OK to send data through the TCM to the Core associated buffer, which is OK to receive (not FULL), the data transmission can continue.
This Advanced System Interconnect is based on AXI-4, allowing easy system integration and high Quality of Service (QoS). The Multi-layer FIC (Fast Inter-Connect) provides low latency high throughput master and slave ports, and the system is based on Multi-level memory architecture using local TCMs.
I also love the “Dynamic Scheduling Scenario” picture, it allows me to feel again like understanding the Dynamic Scheduling in Symmetric System. This allows dynamic task allocation to DSP cores in runtime, but requires software abstraction using tasks oriented APIs and to use shared external memories. Such architecture is more commonly used in wireless infrastructure application (than in terminal).
The move to multi-core processor (DSP or CPU) has lead to implement cache coherency techniques. I think we easily can understand the need for cache coherency, even if the implementation of the concept is all but simple. Once again, the above picture greatly helps understanding cache coherency. Data present in the shared L2 cache can be Core 1 exclusive (red), or shared (orange), or Core 2 exclusive (yellow). The Cache coherency mechanism, HW implemented in each DSP core, will allow the system to properly run.
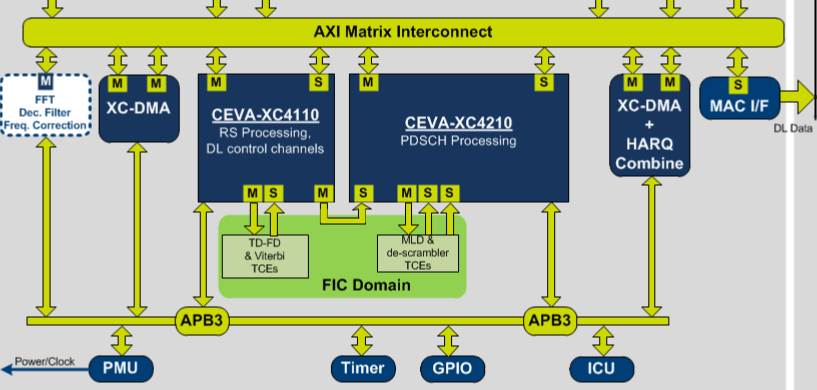
Finally, if we look at the complete view of MUST (above) we better understand why it was necessary to describe the different bloc and concepts, as the complete solution is complex. Let’s also mention Vectored Floating Point Unit (FPU) capability of the DSP core, as well as offloading capabilities: MUST also integrate
co-processors, these Tightly Coupled Extensions (TCE) optimized to support for example FFT or Viterbi, or even User Defined function
The best IP solution has to be back-up by a development board (see above), as well as ESL tools integration with full debug capabilities, compliant with TLM 2.0, with full support for Carbon and Synopsys, to allow smooth design integration and debug, leading to short TTM.
To learn more about CEVA DSP and platforms, visit http://www.ceva-dsp.com/DSP-Cores.html.
Eric Esteve from IPNEST –




Comments
0 Replies to “MUST: DSP ready solution for tomorrow smartphone based on CEVA-XC 4000”
You must register or log in to view/post comments.